

I’ve heard it thrown around in professional circles and how everybody’s doing it wrong, so… who actually does use it?
For smaller teams
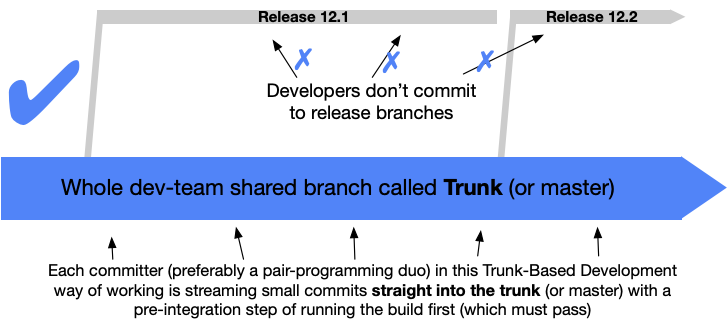
“scaled” trunk based development
You must log in or register to comment.
I’ve heard it thrown around in professional circles and how everybody’s doing it wrong, so… who actually does use it?
For smaller teams
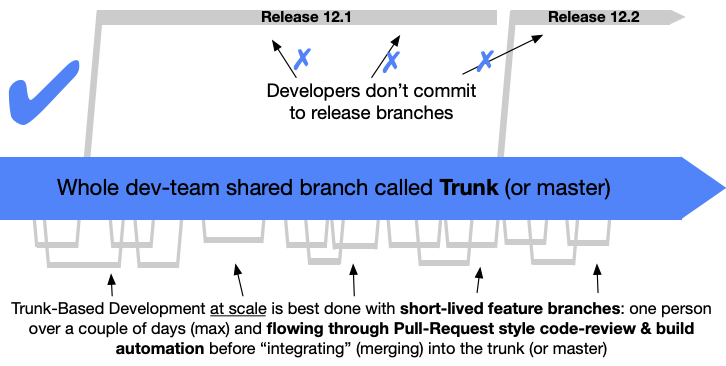
“scaled” trunk based development